This is a lecture 7 of the Systems Engineering curriculum from MIT and edX, Engineering the Space Shuttle.
Links to the lectures:
- Origins of the Space Shuttle or The Making of a new Program
- Development of the Space Shuttle
- Bureaucratic Space War
- Political History of the Space Shuttle
- Space Shuttle Orbiter Subsystems
- Orbiter Structures & Thermal Protection System (TPS)
- Space Shuttle Main Engines
Just a few years before I arrived out of the engineering academy to the space center in 1984 there was an explosion on the launch pad during launch preparation and fueling of a rocket. Back then the number of people killed was told to be around 200. Declassified numbers now give 48 dead. People who were not instantly killed tried to outrun quickly expanding from the explosion hot gas. There is a monument erected to them. The cause of the explosion was leakage of gases. Rocket liquid fuels are very nasty and are incredibly hard to contain. Even small mistakes are not forgiven.

A lot of knowledge, experience, and craft is required to design and build a rocket engine. Tradeoffs are incredibly complex. To launch Russian shuttle Buran (translated as Blizzard), a new Energia (translated as Energy) rocket and a new RD-170 engine were made. Both Buran RD-170 and the Space Shuttle engines used a technique called staged combustion which was a significant improvement on the previous engine designs making them much more efficient due to the extreme rates of energy release but because of that making them at a greater risk of explosion.
There are two key metrics in rocket engine: thrust or the amount of exerted force, and impulse or how efficiently propellant is used. Thrust is the result of the conversion of burning fuel energy into kinetic force. Impulse is the amount of motion a rocket makes per the amount of expended fuel per the amount of time.

To lift the rocket into the orbit both high thrust and high impulse are required. Rocket engines must have the way to force the fuel and oxygen into the combustion chamber at high pressure, the higher the pressure, the better the performance. To achieve that, rocket engines use turbopumps that spin at hundreds of rotations per second. The turbopumps are driven by turbines which are powered by preburners. Preburners burn some fuel and oxygen themselves, it is necessary to make them work, then reinjecting exhaust of burning into the main combustion chamber. It is very hard to build such engines because this design requires several turbopumps, while pressures and flow rates must be delicately balanced. A mistake and the engine will explode.
The space shuttle main engine is fuel-rich, it uses more fuel than oxygen. Buran RD-170 engine is oxygen-rich, it injects extra oxygen into the chamber making it more performant. A derivative from RD-170 is used on the US Atlas rockets. RD-170 was too powerful for Atlas and was modified to accommodate new requirements.

A rocket lifts into space by pushing itself off the fire jet coming from its exhaust. This is a principle of Newtonian mechanics: For every action, there is an equal and opposite reaction. For example, if you throw a rock from a kayak, your kayak will slightly move in the opposite direction of your throw.
Rocket engines were invented by humans centuries ago. In the third century in China, soon after the invention of gunpowder, rockets were used for fireworks and entertainment. Gunpowder engines were quite efficient and easy to make. In the thirteenth century in England Roger Bacon, also known as Doctor Mirabilis, wrote a book describing how to make the gunpowder. In the sixteenth century Conrad Haas pioneered rocket propulsion and designed multi-staged rockets. A century later Kazimierz Siemenovwicz evolved the theory of the rocket design and propulsion. However, until the nineteenth century people did not have the technology to turn those ideas into practice, they remained as designs on paper.
William Congreve in 1805 demonstrated gunpowder-based rockets of unimaginable by those times power. His rockets were mobile and relatively inexpensive compared to artillery but had very low accuracy. By the end of the nineteenth century rifle-bored cannons with significantly improved precision received widespread usage causing military to abandon their interest in rockets.
In 1815 in Russia, Alexander Zasyadko constructed rocket-launching platforms that could fire 6 rockets at a time. He later evolved tactics of the military rocket applications. Zasaydko was also the first person to propose rockets for peaceful space exploration. Flight to the moon on a gunpowder-based rocket engine is described in the book by Jules Verne ‘From the Earth to the Moon’.
It was in 1881 when Russian inventor Nikolai Kibalchich created a theoretical foundation for the rocket engines. Like many inventions in Russia, he did that in prison awaiting his death sentence. This is sarcasm, of course. Kibalchich was behind the assassination attempt on The Tsar Alexander II, he was the man who designed and prepared the projectiles with gelignite, also known as blasting gelatin or simply jelly, used for the assassination. Several days before his execution he documented an original design of a piloted rocket. His design was incorrect, his rocket would have not reached the space.
Konstantin Tsiolkovsky, also from Russia, a simple schoolteacher in a remote town, made enormous contributions to the rocketry. Among his ideas was a liquid rocket engine using mix of hydrogen and oxygen.

In the United States in 1926 Robert Goddard successfully launched liquid-fueled rocket burning gasoline and liquid oxygen.
During the World War 2 Germans under Wernher von Braun worked on a wunderwaffe (‘miracle weapon’) to win the war. His V-2 rockets that Germans used to bomb London later became the foundation for the American Apollo and Russian Soyuz which used the same engineering principles. When I studied in the military academy, we had a real V-2 that we could investigate and learn from!

In 1945 during the operation Paperclip, Wernher von Braun and his V-2 rocket team were taken from Germany to the United States but were not allowed to work on pretty much anything, Americans did not like these ‘Nazis’ and did not trust them thinking that they themselves had the skills and knowledge to build the rockets. It was the success of Russian Sergei Korolev and his Sputnik (translated as Satellite) which shocked American government and freed von Braun and his team to create Apollo. It was May 5, 1961 when Alan Shepard made the first suborbital flight on von Braun’s rocket ‘Redstone’.
But von Braun was behind Korolev. On April 12, 1961 Yuri Gagarin became the first human to make full orbit launched on the rocket ‘Vostok’ (translated as ‘East’).
Von Braun wanted more, and his team started making plans to travel to Mars, but NASA advised him to tone it down and work on something simpler. That became the end of the talented rocketeer.
Then came the space shuttle!
The Space Shuttle Main Engines videos
The most interesting quotes from the lecture:
He thrived on failures because he saw a failure as that’s when you’re on the steepest part of the learning curve.
As I look back, of one of the dumbest things that I did on this program was somewhat associated with the testing. Back early on in the sub-synchronous whirl days we were changing out the turbo machinery after almost every test because we were doing the damage to the bearings. It took about three shifts to change out a turbopump down in Mississippi. Then it took flight time to get the turbopump back to LA and tear it down. We had others in the meantime that we were bringing along but it was very time-consuming. It was in the middle of the summer back in 1975 and a lot of rain showers and that was holding us up because when it was raining or it looked like it was going to rain you couldn’t open up the engine, drop the pump and take it back. That slowed us down. And so I had a brilliant idea! If any of you have ever been down to Mississippi, on those test stands the engine position is on about the fifth level. On about the seventh level I wanted to put a rain shield, a tin roof a couple of levels higher than the engine so the workers wouldn’t have to stop when it was raining. Well, you can probably imagine what happened. That was OK for a while and then we were back into a test and we had a hydrogen leak and we weren’t using the igniters at that time at the end of the bell to burn off the leak so that leak just accumulated on those two stories up to that rain shield. And then, when we went into the test and lit the engine off, the whole Mississippi sky ignited. It burned all the wires. The test was toward the evening. I wasn’t down there at the time to see it but was listening to the test over the phone and the guys almost couldn’t speak. I mean, the whole place went up. I certainly got a lot of ribbing after that.
He encouraged us to test to failure, drive it to failure, know where the cliff was and then back off a sufficient amount and then conduct your certification with cracked blades, with spalled bearings so that it was clear to everybody, it was clear to the people that were running the program and others that had to fly that the problem was understood, we thought reasonably well understood, and it was tested to accommodate that condition.
Images are credit to NASA.

Introduction by Jeff Hoffman (2005)
The space shuttle main engines were one of the most critical development challenges in the whole space shuttle program. Typically, the large engines that power the first stage of a rocket would fall uncontrolled back down to the earth once the stage was jettisoned, never to be used again. Never before had a large rocket engine been designed for multiple uses. Nowadays, the innovative developments made by some of the commercial rocket companies to return, soft-land and reuse the first stages together with the rocket engines, make reusability seem easy. But you need to appreciate that the space shuttle main engines, or SSME’s, as we generally referred to them, were designed decades before the current generation of rockets. Not only were they reusable, but their performance was far superior to any predecessors.
In this lecture you are going to hear from J.R. Thompson who was in charge of SSME development, a real rocket scientist as he is described in the introduction by Aaron Cohen. J.R. refers to several other rocket engines in his lecture: the J2 engine that powered the second stage of the Saturn V using liquid hydrogen as the fuel as did the SSME, and the RL10 engine – America’s first liquid hydrogen rocket engine which powered the high-performance Centaur upper stage.
As in many other space shuttle systems, the heritage of Apollo was critical, both for the left-over infrastructure that was reused for the shuttle, and in the knowledge that was gained during the design and operation of Apollo. Without the massive investments that the US made in the Apollo program, the space shuttle would have been impossible.
J.R. emphasizes the importance of the people who worked on and managed the SSME program. This is an important message to take away from this lecture. Remember, the space shuttle was designed, built and operated by people! In many cases they were trying to do things that had never been done before, which is what makes engineering so challenging and also so rewarding when you are successful.
Another thing to remember is that NASA did not build the space shuttle. NASA does not build rockets or even large satellites. Complex space systems are generally put out for competitive bids by aerospace companies who have their own engineers and managers. Once a contract is given to a successful bidder, NASA then typically works hand-in-hand with the company to ensure that things are going well and to help resolve problems when they arise.
J.R. notes towards the end of the lecture that maybe NASA spent too much time supervising the contractors. I think that his message is finally taken root and as an aside, I should mention that this arrangement has changed radically in the current commercial space flight arena where NASA is contracting for launch services from companies and is giving them much freer hand in the design and testing of their systems. For human spaceflight commercial rockets will still have to meet NASA safety specifications, but NASA is giving companies much more freedom in how they meet the requirements and how they run their tests.
J.R. explains the important certification philosophy of test to failure that was followed in the SSME program: to see what your system is really capable of and understanding all the critical failure modes. As J.R. says, you learn the most in the development program by careful analysis of the failures. He describes the 14 explosions suffered by the SSME’s during the multi-year test program.
I should mention that when my group of space shuttle astronauts came to NASA in the summer of 1978, space shuttle main engine testing was still under way and we saw many vivid videos of SSME’s exploding on the test-stand. Try to imagine what you would feel like seeing these images, knowing that you were some day going to be sitting on top of three of these engines. But, as J.R. points out, in the entire space shuttle program we never have experienced a real engine failure. The only time an engine shut-down during flight was due to a sensor failure which I discuss briefly at the end of this lecture and which you will hear more about in the future lecture by Gordon Fullerton, who was the commander of the flight when this occurred.
From the systems engineering standpoint, a critical take-away from J.R.’s lecture is the trade-off of performance versus robustness and cost. Getting those last few percentage points of performance required for the shuttle ended up being very expensive. The Saturn V second stage hydrogen J2 engine had a combustion chamber pressure of 700 psi. where’s the combustion chamber pressure in the SSME of the space shuttle was in excess of 3,000 psi.
When J.R. talks about opening up the engine throat to decrease pressure and increase reliability, he is looking ahead to the design of NASA’s space launch system which is currently under development and to the various commercial rockets that are now flying.
Some J.R.’s comments are a bit controversial. He believes that the space shuttle program suffered from a bias in favor of high performance at the expense of cost and robustness and he expresses many fears for the remaining years of space shuttle flights. Luckily, there were no further accidents after 2005 and space shuttle main engines remain one of the significant achievements of the space shuttle program.
So now let’s listen to J.R. Thompson talk about rocket science.
Introduction by Aaron Cohen
There were three subsystems on the shuttle that were pressing the state of the art. One was the thermal protection system. The other was the avionic system with the four computers synchronized because, as we explained, the orbiter needs a computer to fly because it is a fly-by-wire system which is statically unstable. The third was the space shuttle main engine. It had high pressure, high temperature and high performance.
Many of you heard the term rocket scientist but you probably don’t really know what that means. Well, today you’re going to meet one, you’re going to meet a true rocket scientist.
J.R. Thompson was responsible for the design, development, test and operation of the space shuttle main engine.
J.R. had a very similar function in the design of the Apollo vehicle. He became director of the Marshall Space Flight Center. Then he was deputy administrator at NASA in Washington. And now he’s president of Orbital Sciences. You’re in for a real treat.
Main Engines
Aaron asked me to consider this talk several months ago and I was a little hesitant at first, but then the more I thought about it, it’s given me a good opportunity to go back and recount some of the highlights and the low points in the program. It was some 30 years ago for me. So, there is some of this that’s going to be still a little fuzzy but there is a lot of it that it’s just like it was yesterday.
The shuttle main engine has its roots back in the technology programs that were funded and came out of Apollo. As early as the mid-1960s people at the Marshall Space Flight Center in the same propulsion group that I was in, although my attention was focused on Apollo at that time, were heavily involved with Pratt & Whitney, Rocketdyne and Aerojet in developing the high-pressure turbomachinery that would one day be envisioned to use in the shuttle, if there ever were a shuttle.
Rocketdyne of North America won the contract in July 13th of 1971. So, shortly after Apollo. Apollo was still winding down when the shuttle Program got its legs and the shuttle main engine was one of the very early awards because it was early on envisioned that that would be what we called back then the long tent pole in the program. It came on the heels of a one-year Phase B competition between Pratt, Rocketdyne and Aerojet. During this Phase B, NASA funded some technology demonstrations, requirements definition and that kind of thing.
Rocketdyne did a very bold demonstration of what they call power head. It was a demonstration of the heart of the engine. It only operated for a short period of time but very high pressure. It was risky. They pulled it off.
It was driven by Paul Castenholz who was coming out of Apollo being there the lead of the team that solved the combustion instability on the F1 engine. Paul was a very ambitious fellow, very aggressive and very bold in trying to capture this award for Rocketdyne.
At that time NASA envisioned what they called a fly back booster. The shuttle main engine was envisioned to be a common engine for the fly back booster as well as the orbiter. In that early concept there would be 12 SSMEs on the backend of the fly back booster operating at 550,000 pounds of vacuum thrust. And on the Orbiter configuration it was three engines operating at 632,000 pounds of thrust in vacuum.
Because of the money that was forecasted at that time and that had been appropriated to date NASA was always behind the power curve in the early phases of the program and they never got everything they wanted. I’m sure that Dale Myers and others that have preceded me have told you the ins and outs of why then NASA scaled back from the fly back booster to the solid rocket motors.
At that point the shuttle main engine was refocused at 470,000 pounds of thrust. That was what’s called the rated power level. At that time there was a full power level and an emergency power level of 109% of the rated thrust that was in the program.
After the award Pratt & Whitney protested. It was a hard-fought competition.
NASA had specified that they wanted an engine bell configuration, a nozzle bell as opposed to Rocketdyne’s aerodynamic spike that they had promoted in the late `60s.
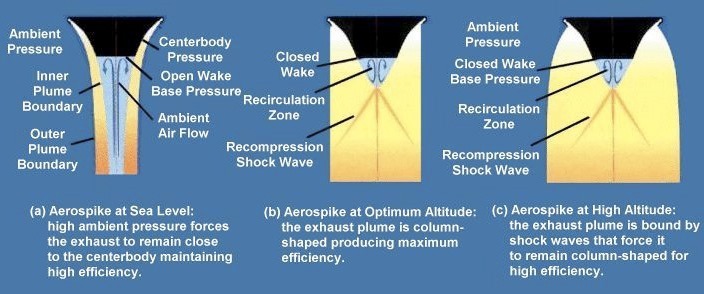



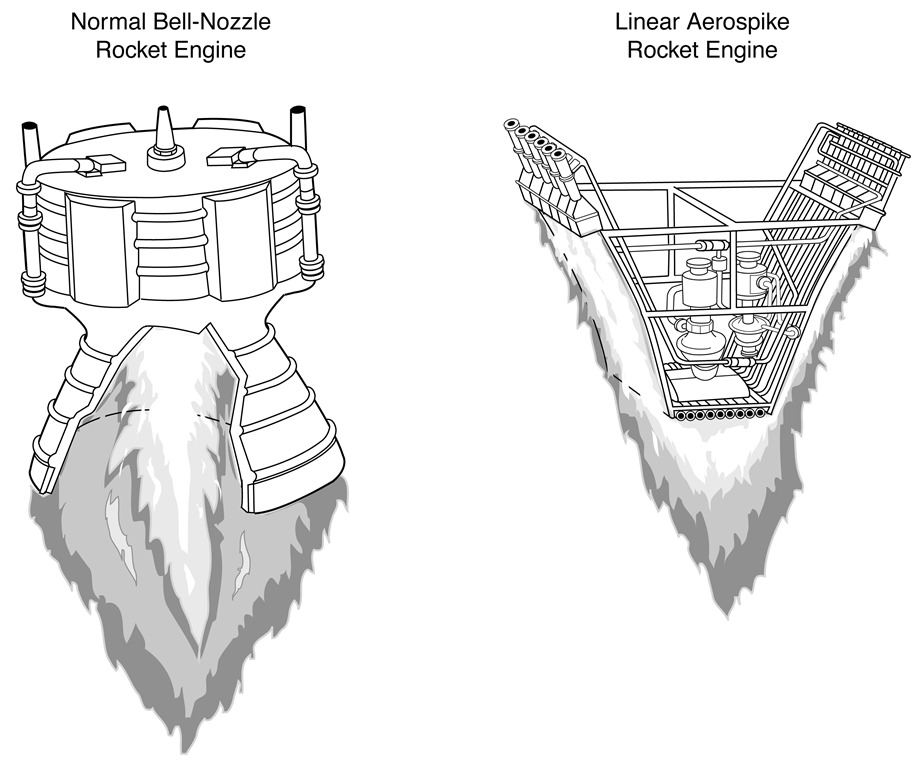
Aerospike is a truncated nozzle. It is packaged and derives the nozzle from the expansion of the gases where the nozzle wall is formed by additional gases that come out in the cooling system. It is a very high performing engine. Its packaging is certainly an advantage where you don’t need a big boat tail, say like you would with the engine. You’re saving about 10 or 12 feet there and the weight that goes along with it.
Pratt & Whitney had been focusing on a bell nozzle all the time and frankly those of us that were on the periphery of this program and still involved in the Apollo figured that Pratt had the advantage in this because Rocketdyne was, of course, awarded the propulsion systems for the Apollo Saturn Program and it was viewed as Pratt & Whitney’s turn. It didn’t turn out that way.
I attribute a lot of that to the good proposal, the boldness and the demonstration program that Rocketdyne accomplished during the competitive period. Anyway, Pratt & Whitney protested. It took about nine months for the protest to be settled. It was settled in favor of Rocketdyne. In the meantime, Rocketdyne was allowed to continue to work with the contractors on the vehicle side because they hadn’t made the selection at that time there. So, they could continue to support their work. In 1972 it was all settled. The contract was awarded cost plus and, as I recall, it was $200 million for the development which was called Phase A, and $200 million for the production which was called Phase B and the Phase B program included 26 production engines. I won’t comment as to what the costs eventually grew to, but very substantially beyond that.
Let me highlight for you the characteristics of the engine.

I mentioned the thrust levels. The rated power level was 470,000 pounds. It had the capability, if an engine was out early and you wanted to abort the orbit, to throttle the engine up to 109% of the rated thrust that was called full power level. Early on in the program it was termed emergency power level. At the rated conditions it accommodated or required a little over 3,000 pounds per square inch chamber pressure in the combustion chamber. The area ratio of the nozzle was 77:1. It had a very good specific impulse, about 453, 454. That compares to J2 in Apollo of about 442. Weight was about 7,000 pounds.
Life was 7.5 hours and 55 missions. That’s quite misleading, though, let me tell you, and I’ll comment more on this as we go through.
It was a tough development program. It took from 1972 through first flight in 1981. I joined the program after Apollo and after Skylab in May of 1974 and it was torture from there until the first flight in April of 1981.
Early on it was envisioned that the SSME would be used for both the fly back booster and the orbiter configuration. It would use basically the same power head. You would just change out the nozzles to give you the two engine thrust levels. It was rather simple in that concept. Of course, that’s not the way it worked out. It went to one configuration to service the orbiter and everything was optimized and focused on that.
Let me say a few words about the schematic itself and what the engine looked like.

In conceptual terms, it had two low pressure pumps which were required to give the proper inlet pressures to both high pressure pumps to avoid cavitation. It had two high pressure pumps. It was all fed through a common power head to a thrust chamber assembly and then into the nozzle.
Starting on the fuel side, the fuel pump increased the pressure to about 300 pounds per square inch. And then that went into the high-pressure pump on the fuel side where the pressure was boosted to a little over 6,000 pounds per square inch.
About 80% of the fuel all went to the two pre-burners, the fuel and the oxidizer pre-burner, contrasted to about 12% of the oxidizer. That was to provide a very fuel rich power system to drive the two turbines, the high-pressure fuel pump turbine and the LOX pump turbine.
The turbine temperatures were in the range of 1750 degrees air ranking.
Almost all of the housing structure on probably 80% of the engine was Inconel, very tough steel, able to take very high pressures. The combustion pressure in the chamber was about 3,000 pounds per square inch. At the entry to the pre-burners the pressure could get up to 8,000 pounds per square inch. It was a very high-pressure system up and down.
It was all in series. This was the way they achieved the high efficiency. All of the propellant came through the low-pressure system, the high-pressure system into the pre-burners, in through the cooling circuits, all in the hot gas manifold, all in the main chamber, all of it exited the nozzle. None was dumped overboard to simplify the flow pad. A good bit of the fuel at the exit of the high-pressure pump went directly to feed the two pre-burners. A good bit of it, about 20% of it went to cool the nozzle, then up through and drove the turbine because, having cooled the nozzle, it was converted to a warm gas which then drove the low pressure turbine, came back in and was captured and served to cool the shell of the hot gas manifold.
The same similar thing on the oxidizer side.
The speed of the low-pressure fuel pump was about 15,000 rpm and high-pressure fuel pump about 35,000 rpm. The speed of the low-pressure LOX pump was 5,000 rpm and of the high-pressure oxidizer pump about 30,000 rpm.
The discharge of the low-pressure LOX pump was about 250 pounds per square inch entered into the main LOX pump where the pressure was elevated to 4500 pounds per square inch. Then it went some to the pre-burners and the rest directly into the main combustion chamber. Some part of the LOX flow then was further boosted to about a little over 8,000 pounds per square inch, which fed the oxidizer into the two pre-burners.
It was a very efficient cycle, very high-pressured cycle.
A couple other features that you don’t see on this chart, there was a heat exchanger wrapped around the high-pressure oxidizer turbo pump turbine which served to preheat gas to pressurize the oxidizer tank.
Those are the major points that I would make on the cycle itself.
There were few problems with the two low-pressure pumps. A lot of technology was in the high-pressure pumps, both fuel and oxidizer. The main problem with the high-pressure fuel pump was sub-synchronous whirl. It was a very traumatic time in the early period of developing the shuttle main engine. It caused a lot of delays. A tough problem to solve. Then there were high-pressure oxidizer turbopump bearing overloads, LOX fires, explosions. That was probably the single toughest component to developing the program.
Because they had such a head start in planning for the development of this program, early on it was planned to be done in a very methodical way. When I say they I’m talking about the people at Marshall with the people at Rocketdyne. They had very elaborate system of design verification systems where you couldn’t progress to the next stage until you had passed certain testing on a valve or on a low-pressure pump.
All this was envisioned to be done on the component test facilities at Santa Suzanna which is right out a short distance from Canova Park up in the mountain that both NASA and Rocketdyne owned up at that time and that were carried over and upgraded from the Apollo program.
But because of the high pressures involved development of this high-pressure turbomachinery became a very expensive undertaking, a lot of money, too much time, huge facilities, valves that were probably as big as a wall of a small conference room.
It became clear early in the program that that very methodical way of developing the engine, and that is, before we go to an engine system test let’s develop it at the component level so we eliminate those problems, although theoretically it sounded very good it just didn’t work. The facilities were not available in time to do that and the money was going to be exorbitant. It became clear that we were going to have to develop the components in parallel with the engine test.
It was the biggest systems engineering challenge that I think we had in the shuttle program. Certainly, there were a lot of challenges in major systems, integrating the shuttle engine into the Orbiter, for example. But down at the engine level, to develop those components: the two low pressure pumps, the two high pressure pumps, the pre-burners, the hot gas manifold, the main injector, all the control valves. And then we also had on the engine, which I didn’t show on the schematic, a computer, redundant computers that were cross-strapped so that the input or the output could be cross-strapped and be very tolerant to failure.

We went to what we call an integrated subsystem test bed, ISTB. That became the bobtail engine of the program. Bobtail was a 35:1 area ratio nozzle which allows us to not only start the engine but to operate it at the throttle condition 50% of the rated thrust and the nozzle would still flow full. It would not separate. And so then we could proceed with the development of the testing or the development of the engine program.
It was an efficient way to go about the program so we didn’t stall. It was tough because we had to solve the engine problems in parallel with the component problems, all at the same time. And sometimes it was hard to tell which was the problem.
We started our first test in May of 1975. That is me there on the left, and Norm Reuel who replaced Paul Castenholz there in the center, and Dom Sanchini who I view to this day as the strength of the main engine program who eventually replaced Norm.
A few comments on the evolution of some of the people on the contractor side. I mentioned Paul Castenholz who to me was the key to Rocketdyne winning the program. At that time, and this is a personal view, I think Rocketdyne took a big sigh of relief after they won the contract, probably relaxed a little too long, got in trouble up at Santa Susanna in not developing that component facility. The test control centers up there, Coke bottles were laying around, so it was not a well-disciplined operation. They had gotten lax, I guess, was the best way to say it.
Norm Reuel came in to run the program at the request of NASA. He had done the same job on a J2 and other programs within Rocketdyne for the Saturn Program and worked with me and the other fellows at Marshall.
And we appointed Dom to drive this ISTB to help us learn how to start the engine, to how we could properly integrate a number of the components into the engine, and proved in the long-run to be a very valuable tool.

This chart depicts the buildup of run time on the engine. Test seconds are plotted on the right in thousands, the number of tests plotted on the left, and the year is shown below.
We started in 1975. We finally flew in April of 1981 on STS-1.
I’ve highlighted along the way 14 major engine explosions all of which were very traumatic in themselves. I’ll show you some pictures shortly of what an engine looks like after it goes through that and then you can extrapolate that to envision what was in the boat tail of the Orbiter had it occurred in flight and what it would have done to the flight itself.
The test seconds curve is in the middle. You can see the long plateau of about nine months between 1976 and 1977 where a combination of learning to properly ignite the engine without over-temping the turbine blades or other parts of the turbine combined with what I’ll call this sub-synchronous whirl on the high pressure fuel pump.
Sub-synchronous whirl, there is a very exotic definition of it, but it’s an orbiting of the shaft within the bearings themselves caused by a softening of that system. And you can imagine the softening is attributed to overheating of the bearings, you don’t have the stiffness, and so this allows the rotor to orbit there, vibrations get very high and we have to shut the engine down.
About 2.35 seconds was the nominal time before we would encounter this very high vibration causing the engine to stall and forcing us to shut the engine down.
It manifested itself in overheating of the bearings, spalling of the bearings in their raceways.
The speed of the rotor of a turbine at that time was probably in the 15,000 rpm before you could catch the engine and shut it down operating for a second or a half a second with those high side-loads, inadequate cooling, overheating of the bearings. You’d get the bearings back and you’d put them in your hand and they were damaged.
The engine and the turbomachinery were located down in Mississippi where we were doing the testing. It wasn’t like you could just try it again. You had to bring it all back, replace the bearings, try to figure out what the problem was and put in some kind of a fix. We went through a number of fixes trying to stiffen the system so we could be able to tolerate and drive through.
I thought at that time that if we could ever get through this period then we would be all right.
High Pressure Fuel Turbopump Kaiser Hat Nut
Engine 2013. Test 901-364. 7 April 1982
Failure Cause:
Experimental nut and washer stack had a sneak leak path which allowed hot gas to impinge on the Kaiser hat causing it to crack. Hot gas then entered the bearing coolant cavity and destroyed the bearings. Sudden flow stoppage ruptured the pump inlet and the extreme LOX rich combustion burned the engine out of the test stand. Unsuccessful termination of FPLC cycle.
Design Solution:
The harsh environment was improved enough to eliminate erosion. A Flight redline was added for HPFTP turbine temperature. Engine 2014 assigned as second FPLC engine.


This is a high-pressure fuel turbopump. The sub-synchronous whirl and the overheating of the bearings occurred on the turbine side. The coolant path, you come through some labyrinth seals here, you go down the passage, up through the center of the shaft and in through some provisions that were made to cool the bearings on a turbine end.
We brought in a lot of external consultants and had a lot of cooperation from people across the country. After nine months it was one of the internal guys at Rocketdyne, Joe Stangeland, and some of the people in his turbomachinery group that came up with the idea that there was a vortex that was occurring in this cavity on a turbine end and what we had to do was to kill that vortex and then allow the coolant to go through.
He put a little thing, what he called a paddle, about the size of dime, that was screwed to the rotor. After we included the paddle the engine went right up to the minimum power level. That was the power level we had set and planned all of the tests to accelerate to.
This problem number one was just being able to understand and accommodate the start sequence. You had to start the engine fuel rich. Any excessive oxidizer would give you a cutoff because of all the sensors that we had.
The second problem and the one that causes the most time that I’ve mentioned is the high-pressure fuel turbopump sub-synchronous whirl.
And then problem number three are the LOX pump explosions. They could be triggered by loss of a turbine blade on a turbine end which would unbalance the rotor, overload the bearings and then cause a LOX rich fire which very quickly consumed the whole engine. Bearing problems and turbine blades were the major problem that caused the LOX pump explosions. There were numerous, four highlighted on the test chart under number 3.
Turbine blades had very limited life, cracks would grow. At that time we didn’t understand how long we could run them before we had to replace them, so we went to dampers on the turbine blades. That eventually solved the vibration of the blades within the turbine wheel stack and allowed us to proceed. Whether that caused the imbalance of the rotor or primarily driven by bearing problems, we used ball bearings in the Rocketdyne turbomachinery. Later in the program we had gone to roller bearings developed by Pratt & Whitney.
We had some other problems. I’ve noted a fuel pre-burner burn through (number 4 FPB), just a structural burn through.
The only problems on the engine were nozzle steer horn failures (number 7). That was a structural feed line that was in the shape of a steer horn at the aft end of the bell nozzle. We had two of those structural failures and they were very traumatic for the program. As soon as you lose the coolant to the nozzle you start shutting down a lot of the engine system LOX rich which causes a fire.
We had 1,080 tubes that made up the nozzle that we flowed the hydrogen through to keep the nozzle cool. 1,080 of them! And we had a number of nuisance cracks or splits in those tubes that we learned to live with. We learned to go out and put a cap on them post-flight, braise over and just cap off the leak.
The J2 chamber pressure was about 700 pounds per square inch. RL10, which was the first LOX/hydrogen engine in the country developed by Pratt & Whitney, chamber pressure was a couple hundred pounds per square inch. The shuttle main engine had the pressures 3,000 and up to 8,000 pounds per square inch. This was a real push. Was it worth it? As you look back on the engine, you’ve now taken into orbit over 300 of these engines and 100 flights, three at a time. You have had one shut down because of a safety sensor that failed and shut one engine down in flight and we were far enough along in the flight so we aborted to orbit and the other two burned a little longer and went to orbit. But it was a very costly program.
High Pressure Oxidizer Turbopump Explosions
Engine 0103. Test 902-120. 18 July 1978
Failure Cause: Special capacitance probe installed internal to the pump contacted the rotor, starting a fire. Flow blockage pressure surge ruptured LPOTP
Design Solution: Avoid complicated internal instrumentation


When you’re in the middle of a development program you’ve got a lot of budget pressures, you’ve got the shuttle’s first flight date changed several times, you’ve got all that hanging over your head, and then you’re called to Mississippi on a test and you look down on the engine and that’s what it looks like, it’s like a kick in the stomach. You’ve got to start all over. That mental picture was in our minds 14 times in this program where you had to start over. Recovery typically took about a month. We formed a team within Rocketdyne and one within NASA to go solve the problem. Half of the time the problem fairly evident quickly after the test. Sometimes it took a couple of weeks to narrow it down: it could have been this or that. And then you fix both ‘this or that’ not knowing exactly what it was. It was a very tedious and time-consuming, we were testing around the clock. If it occurred during the holidays you just cancelled your holidays and jumped in, and we did what we had to do.
As I look back, of one of the dumbest things that I did on this program was somewhat associated with the testing. Back early on in the sub-synchronous whirl days we were changing out the turbo machinery after almost every test because we were doing the damage to the bearings. It took about three shifts to change out a turbopump down in Mississippi. Then it took flight time to get the turbopump back to LA and tear it down. We had others in the meantime that we were bringing along but it was very time-consuming. It was in the middle of the summer back in 1975 and a lot of rain showers and that was holding us up because when it was raining or it looked like it was going to rain you couldn’t open up the engine, drop the pump and take it back. That slowed us down.
And so I had a brilliant idea! If any of you have ever been down to Mississippi, on those test stands the engine position is on about the fifth level. On about the seventh level I wanted to put a rain shield, a tin roof a couple of levels higher than the engine so the workers wouldn’t have to stop when it was raining. Well, you can probably imagine what happened. That was OK for a while and then we were back into a test and we had a hydrogen leak and we weren’t using the igniters at that time at the end of the bell to burn off the leak so that leak just accumulated on those two stories up to that rain shield. And then, when we went into the test and lit the engine off, the whole Mississippi sky ignited. It burned all the wires. The test was toward the evening. I wasn’t down there at the time to see it but was listening to the test over the phone and the guys almost couldn’t speak. I mean, the whole place went up. I certainly got a lot of ribbing after that.
I might mention that just this last summer I attended a little event there in Huntsville where the Rocketdyne team came down and now the engine program had just passed its millionth test second mark. For STS-1 the total test seconds were about 110,000. A little over half of that, 65,000, almost 70,000 were at the rated conditions, the conditions you flew it at. It’s gone up by about a factor of ten in the meantime.

Another key to the shuttle engine program was the philosophy imparted by John Yardley. He recognized early on that we had bitten off probably a little bit more than we could chew. To have an engine that you could solve the problems of where you put the bearings in there. You ran them for five starts and they came out in pristine condition – that wasn’t going to happen. In the earlier view graph I had said 55 starts! And the turbine blades, one blade failure, I forget how many are in those two stages on that wheel, probably well over a hundred, but one would offset or offload the balance on that rotor, then you would overload the bearings going at the high speed of the 35,000 rpm’s and would fail it. You just could not tolerate a failure in the turbine blades, but in evidence after testing, where you can tear the blades down and de-stack them and look at them under a microscope, you could see fatigue cracks.
All of us, but John provided the leadership, recognized this fact, and if the requirement were going to be that you wouldn’t fly with turbine blade cracks, we weren’t going to fly. He encouraged us to test to failure, drive it to failure, know where the cliff was and then back off a sufficient amount and then conduct your certification with cracked blades, with spalled bearings so that it was clear to everybody, it was clear to the people that were running the program and others that had to fly that the problem was understood, we thought reasonably well understood, and it was tested to accommodate that condition.
That was the philosophy that was engrained in the shuttle. And probably not enough in some of the other areas. The shuttle Engine Program was a little bit blessed with this fear of failure, it’s the toughest technical problem so we got the most money. It’s not all a downside. We got the money to build the test depth that provided the insight to the shuttle managers that could make the call as to when we were ready to go.
The squeaky wheel gets oiled!
I contrast that with maybe the famous O rings on the booster. That was a problem that was observed, a few tests were run, but not enough, not to failure. It wasn’t ever tested to failure! On the ground it was tested so you could see that the O rings were split maybe, but not to be staring at a picture like that as to what is going to happen when that O ring gives and very quickly can burn through.
The other example I would make is a tank. And this is the most frustrating to me because early on we all saw some of that foam come off, but not in the sized pieces that the shuttle program saw three flights before Columbia. That was a big piece of foam, it came straight down the vehicle, it made a small dent in the aft skirt of the solid rocket boosters that were subsequently recovered. That should have been an eye-opener that that piece of foam doesn’t always have to go straight down the side of that vehicle. It could get out in the slip stream and hit a wing or something.
That type of testing was never done whereas on the engine program there were a number of flaws that were accommodated and we felt comfortable with.
Now, you go and read the Challenger report, you read the Columbia report, and they will almost tell you that NASA became comfortable with flaws and that lead to the problem. I take issue with that. I viewed it different because that was almost the foundation of the shuttle Engine Program. It was built on flaws. It was tested so wherever the soft spots were, you knew it and you attacked it and tested it in the appropriate way.
I keep coming back to John Yardley. As a part of the certification program prior to the first Orbiter flight there were eight certifications completed. One of those certifications that included 13 tests was to be conducted. One was abort to orbit which was 623 seconds. A nominal shuttle test or mission is 520 seconds. Then an RTLS, return to launch site is 820 something seconds. It had a mix of those in there. The engine had some FPL, full power level. It was tested at all of the limits. In some of those certifications we had to go into the test with cracked turbine blades. We started the test with a known crack and we knew by analysis what its growth rate was that we had judged from other tests. We planted blades that did that. We did the same thing with bearings. One time both Dom Sanchini and I were trying to get the most on every test. We put cracked blades and spalled balls and combined them all in a test. Now, Yardley didn’t mean that. He didn’t want to go that far. But there was a lot of NASA leadership that bucked up the back of the program managers, both myself and Sanchini. I mean, they knew the way to develop the confidence in this engine was to test it.
And that became the theme. That isn’t true today. And that’s what I worry about.
I will say a few more words about Dom Sanchini. He passed away about 15 years ago, probably in his early sixties. He was the deputy program manager on the F1 engine to Paul Castenholz. A good engineer. He was a lawyer by trade, but he had also accumulated a good background well steeped in engineering. He was a hard driver. He thrived on failures because he saw a failure as that’s when you’re on the steepest part of the learning curve. You never learn more than in the aftermath of a failure where you’re forced to go through and look at all of the data and postulate a lot of other different failure modes. He thrived on it and he made sure that the whole Rocketdyne team viewed it in that light. He was a real strength to the program.
The shuttle engine, back in the hay-day or the time period when we were in the development program, we were building them around the clock out of Canova Park, three shifts out on a manufacturing floor, probably at a rate of about one a month, ten a year. A pretty high production right there.
A shuttle engine costs by my last count about $40 million. I imagine in today’s money it’s probably closer to $60 million a copy. But today they build about three-quarters of an engine a year! The production rate is way down.
The testing now is very infrequent. That’s to save money. And that’s the Achilles’ heel of the shuttle program.
If you’re not going to do it right, whether you cannot afford to do it right or you have other ambitions, for example you want to do something else in the space program or within NASA, you probably ought to stop it because it’s going to be the next failure if you don’t treat it right.
The shuttle program is a little over almost 3.5 decades old. That’s at a minimum two generational changes and a lot of small businesses that support the shuttle program. And so you’re going to lose a lot of the knowledge when you have the turnover of these generational changes. Little things.
When you look back, one of the major disappointments or traumatic times in the program was back in the late 1970s when we were building the first three engines that would power Columbia on STS-1. When we were building those engines we had a mix-up of well wire in the Canoga plan. One well wire could take a heat treat and the other one couldn’t take a heat treat. That was a mom and pop operation that came in, got the well wire, took it home and cleaned it and then delivered it back in baskets to Rocketdyne. Well, they got it mixed up. And so we built the first three flight engines with well wire that would not take a heat treat that we depended on. You go out and look at those engines with inches and inches and rows and rows of wells that are not to the proper heat treat. We had to go through and analyze every section and over-test those engines at a little higher pressure than we normally would have to be able to show that having been built with the wrong well wire it was still good enough because the design was up to FPL and a little beyond, that it could still take it and operate at the rated thrust condition.
As you know and you read, NASA is at a very critical time today. They’ve got to make some decisions in terms of where their priorities are and what they want to try to do. They don’t want to spend money on the shuttle because they seem to be committed to replacing it. And if that’s what you’re going to do, that’s what you’re going to do.
But between now (2005) and 2010, if that’s the year they choose to retire the shuttle, they are not going to be motivated to test. The program is going to be at more risk over the next four years than it was in the first four years because of that reason. You don’t know where the ledges are, where the cliffs are and testing once a month or once every two months is just not going to do it.
Looking back and knowing the capability of the shuttle and being somewhat troubled, quite a bit troubled by what I hear and read about NASA wanting to retire it, although I understand their reasoning. Some view it as a flawed design. I don’t view it as a flawed design. You need to relook at how you operate it. I hadn’t been particularly pleased with the operation of the shuttle. Watching all this foam fall off and not even raising your hand. But then, after all that occurred, nobody stopped and stripped all that foam off and maybe replaced it with cork that’s heavier, that’s got some tensile strength that you can anchor it on there with glue or whatever you want to do. And it’s going to cost you some performance.
NASA has been biased too much. And they certainly started this in the shuttle main engine in the direction of performance where if you back off a little bit, the system will be a lot more robust, serve you a lot better over the long haul, and maybe you don’t push too much in some of these directions that have got us in trouble.
I’ll just give one statistic that I remember really impressed me during our initial astronaut training when they were talking about the main engine. The high pressure turbopump is a device that is about the size of a typical automobile engine. It produces 50,000 horsepower just to pump the liquid oxygen at high pressure. That really gets your attention. When you talk about pushing the state of the art and trying to get a lot of power out of a small volume, that just really amazed me.
In summary, if I look back on the program, there were two key components that were paramount to the success that the shuttle engine enjoyed. One was a decision to use the Integrated Subsystem Test Be (ISTB), to get away from the serial component test and then the systems test to try to combine it and do a systems engineering job from day one. And the other one which may be a little bit more important, but just as important, was the philosophy in the program of test to failure. Know where the failures are.
